Использование генеративных моделей ИИ в сфере пожарной профилактики – перспективы и вызовы

Кратко о проблеме
Особенностью современных средств информирования стоит признать необходимость адаптации к использованию быстро меняющихся технологий. Одной из важнейших сфер, где внедрение инновационных решений на основе генеративных моделей нейросетей способно принести значительные преимущества, является область пожарной профилактики. Стоящие перед специалистами данной сферы задачи – подготовка методических рекомендаций, инструкций, обучающих и информационных материалов - требуют умения не просто анализировать меняющуюся нормативно-правовую базу, но и преобразовывать актуальную информацию в доступную непрофессионалам (обычным людям) форму.
Подготовка материалов по противопожарной пропаганде традиционными методами требует больших временных затрат, даже при условии владения навыками работы в программах графического дизайна, видеообработки изображений и т.п. В условиях постоянно растущей нагрузки на сотрудников органов государственного пожарного надзора практически нереально уделять должное время для качественной подготовки подобных информационных материалов.
Возможности искусственного интеллекта
Прогресс в сфере информационных технологий открывает новые возможности, одной из которых является применение генеративных моделей искусственного интеллекта (ИИ). Эти модели способны создавать уникальный контент, обрабатывать большие объемы данных и ускорять процессы разработки учебных и методических пособий, руководств, буклетов, информационных материалов, постов, размещаемых в социальных сетях. Среди разрабатываемых моделей существует своя “специализация” - деление на те, что создают графический, аудиовизуальный или текстовый (языковой) контент. Последние, например, наиболее просты в освоении, не требуют владения навыками программирования и широко используются специалистами, работающими в сфере информирования и пожарной пропаганды.
Что представляют собой генеративные модели?
Генеративные языковые модели искусственного интеллекта (large language model, LLM) – это сложная математическая структура, созданная специально для работы с естественным языком. Такие модели проходят обучение на больших массивах текстовых данных, что позволяет им эффективно справляться с множеством задач, связанных с обработкой, пониманием и созданием текста. В процессе обучения эти модели изучают закономерности и структуру языка, что помогает им анализировать тексты, извлекать смысловые единицы, генерировать новые предложения и интерпретировать уже существующие данные. Сегодня Россия располагает собственными конкурентоспособными решениями, соответствующими международным стандартам и пригодными для использования в государственном секторе, бизнесе и частной жизни.
Среди множества существующих нейросетевых моделей наибольшую популярность среди российских пользователей приобрели отечественные проекты, созданные крупными компаниями и научными организациями. Согласно актуальным исследованиям и рейтингам, наиболее востребованными и эффективными моделями в России стали:
- Alice AI LLM от “Яндекса”, демонстрирующая высочайшие показатели в бенчмарке SLAVA*. Данная модель способна правильно отвечать на вопросы, касающиеся национальных ценностей и исторических аспектов, делая ее идеальной для образовательного и официального использования. Помимо отличных результатов в области русской языковой специфики, модель отличается простотой интеграции и наличием широкой экосистемы продуктов, таких как «Яндекс.Облако».
- GigaChat 2 Max от Сбера – признанная одна из лучших моделей для профессионального использования. Отличительной чертой является высокое качество генерации естественного языка, большая длина контекста и способность поддерживать сложные многошаговые диалоги. Сбербанк сделал ставку на открытость и доступность своей модели, предлагая широкий спектр вариантов лицензирования, что позволило ей завоевать доверие российских специалистов.
- YandexGPT 5.1 Pro – основное отличие от базовой версии Alice AI LLM – повышенная надежность и лучшая адаптация под профессиональные задачи. Модель хорошо справляется с обработкой сложного текста, созданием документации и аналитическими задачами.
Помимо перечисленных моделей, широкое распространение получили и такие зарубежные проекты, доступные российским пользователям, как ChatGPT и DeepSeek, преимущество которых – наличие памяти, позволяющей вести непрерывные беседы и запоминать предыдущие запросы, что улучшает качество ответов. Однако для российских пользователей в данных моделях могут быть ограничены некоторые функциональные особенности.
Интеграция российских языковых моделей ИИ с государственными информационными системами стала ключевым вопросом цифровой трансформации в стране. По состоянию на 2025 год отмечается тенденция к активному внедрению технологий ИИ в государственный сектор. LLM играют особую роль в развитии цифрового правительства, оказывая существенное влияние на улучшение качества предоставления услуг гражданам и организациям.
Современные генеративные модели предлагают массу возможностей для специалистов в области пожарной профилактики:
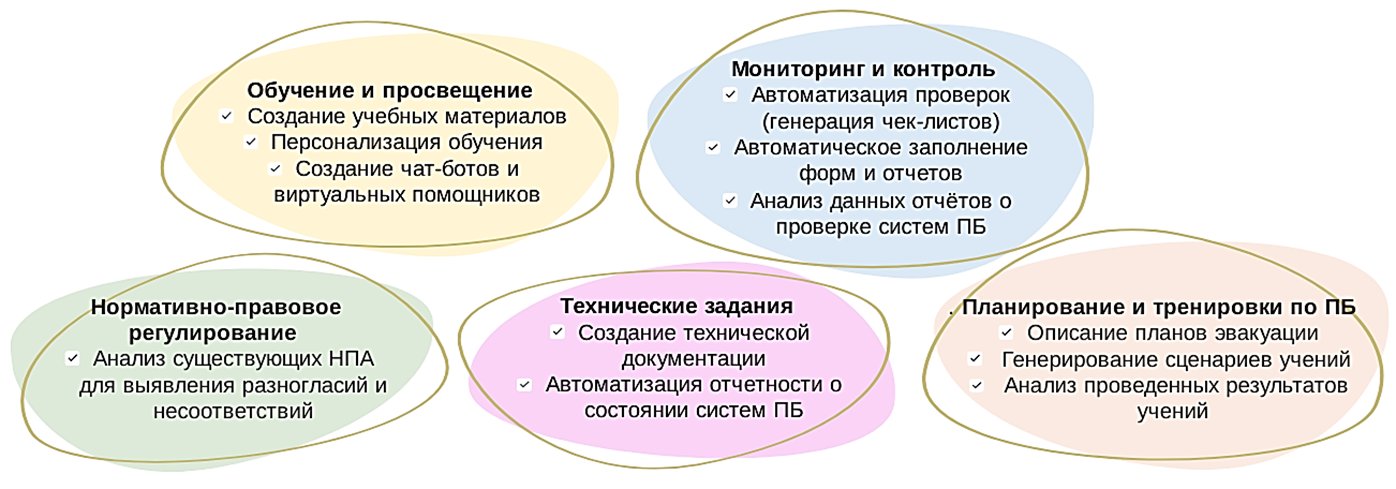
Кроме LLM наиболее эффективным направлением использования генеративных моделей можно считать генерацию изображений, видеороликов и аудиозаписей. Современные нейросети могут создавать реалистичные визуализации зданий, оборудования и конструкций, демонстрируя последствия неправильного обращения с огнем или нарушение правил хранения горючих материалов. Подобные демонстрации способны оказать значительное влияние на аудиторию, усиливая эффект воздействия учебного материала. В этом плане показателен опыт американской компании - производителя датчиков СО. Традиционные ролики с объяснениями угроз, исходящих от угарного газа не работали, пока с помощью ИИ-анимации не была создана серия "хоррор-роликов", где "злодеем" был угарный газ. В результате охват кампании превысил плановый на 30%.
Взяв на себя рутинные задачи генеративные ИИ могут значительно повысить эффективность пожарной профилактики, сделав систему предотвращения пожаров более надежной и адаптированной к современным условиям за счет разнообразия и быстродействия. Однако кроме очевидных преимуществ интеграции средств искусственного интеллекта в работу органов ГПС МЧС России следует учитывать и возникающие сложности и ограничения:
- качество генерируемого контента и риск фактических ошибок ("галлюцинации" ИИ). Даже обученные на профессионально ориентированных данных модели иногда допускают грубые ошибки, неверно интерпретируя факты. Особенно остро проблема проявляется при создании технической документации, инструкций и нормативных актов, где малейшие неточности могут привести к серьезным последствиям. ИИ может генерировать уверенно звучащий, но неверный текст. Поэтому все материалы, созданные нейросетью, обязательно должны проверяться специалистами на соответствие техническим и этическим нормам и реальным данным (фактчекинг). Именно поэтому большое внимание следует уделять обучению сотрудников работе с ИИ. По сути ИИ – это инструмент, а не замена эксперту. Лучшие результаты достигаются при исполнении алгоритма: эксперт задает смыслы → ИИ «упаковывает» в слова или графический контент → эксперт проверяет и при необходимости корректирует результат.
- обучение и эксплуатация мощных генеративных моделей требуют значительных вычислительных мощностей и затрат электроэнергии. Для организаций, работающих в области пожарной профилактики, дополнительные расходы на инфраструктуру могут стать препятствием для полноценного перехода на технологию ИИ.
Анализ публикаций и высказываний экспертов свидетельствует о растущем значении отечественных языковых моделей ИИ для государственных структур. Возможность интеграции таких моделей в существующие информационные системы обещает упростить взаимодействие граждан с органами власти, повысить прозрачность процедур и облегчить доступ к услугам.
Заключение
Следовательно, интеграция российских языковых моделей ИИ с государственными информационными системами представляется перспективным направлением, способствующим улучшению качества обслуживания и укреплению позиций России в международной конкуренции на рынке технологий искусственного интеллекта.
* - бенчмарк SLAVA (Sociopolitical Landscape and Value Analysis) – инструмент, разработанный для оценки качества ответов больших языковых моделей (LLM) на вопросы, имеющие значение для российской аудитории. В рамках этого бенчмарка собрано более 14 тысяч вопросов, охватывающих ключевые области: историю, географию, обществознание и политологию. Это уникальное исследование направлено на понимание того, как LLM справляются с вопросами, имеющими значимость для российской аудитории.


